
Publiceret på https://pro.ing.dk/4206
Dette synspunkt er det andet i en tredelt føljeton, hvor de dataetiske udfordringer ved automatiseret beslutningsstøtte til sagsbehandling vendes. I denne anden del er fokus på clustering og predictive analytics.
Brugen af teknologi til at understøtte manuelle beslutninger taget af sagsbehandlerne i offentlige myndigheder er under hastig udbredelse. Beslutningsstøtten bringes i anvendelse, fordi den både bidrager til at gøre sagsbehandlingen mere ensartet og til at frigøre medarbejdere fra de mere rutineprægede opgaver til at fokusere på de mest væsentlige. Automatiseret beslutningsstøtte handler derfor ikke om at erstatte sagsbehandlerne, men om at drage fordel af de bedste egenskaber ved både mennesker og teknologi.
Beslutningsstøtten kan basalt set kategoriseres efter tre faser:
- Assisteret informationsindsamling – anvendelse af avanceret analyse til at raffinere dataindsamling fra infrastruktur-teknologier som cloud, datalakes mv. til at understøtte manuelle beslutninger.
- Augmented informationsindsamling – hvor machine learning-modeller inddrages oven på eksisterende informationssystemer til at understøtte og simplificere beslutninger taget af sagsbehandlere.
- Autonom informationsindsamling. Her er processerne fuldt digitaliseret og automatiseret hele vejen til at levere information, som maskiner, chatbots og systemer kan handle ud fra.
I dette synspunkt ser vi nærmere på brugen af augmented informationsindsamling og de dataetiske udfordringer, der er knyttet til anvendelsen af dem.
Segmentering og prioritering af sager
I sidste uge behandlede vi analyse af tekst i sagshåndtering. Men avanceret analyse kan også hjælpe på andre måder end ved at forstå teksten i klagesagen. Lad os se på klagesagsbehandlingen i en styrelse.
Når klagen ligger på styrelsens bord, og bilagene er gennemlæst, forberedt og kommenteret af den kunstige intelligens, skal sagen gennemlæses af en sagsbehandler. Nogle sagsbehandlere er hurtigere end andre. Lad os antage, at en erfaren sagsbehandler kan afgøre en sag hurtigere end en nyansat. Hvis styrelsen ansætter 200 nye medarbejdere frem mod 2020, vil de nye medarbejdere ikke have samme erfaring og må forventes at arbejde mindre effektivt end de erfarne ressourcer. Hvis de ikke kan afgøre en sag, må de lade sagen overgå til en mere erfaren sagsbehandler, og så er der to ressourcer, der har brugt tid på at sætte sig ind i den pågældende sag.
I stedet kan man få en selvlærende machine learning-model til at segmentere ankesagerne efter kompleksitet og kompetencebehov. Det vil gøre muligt at dirigere ankesagerne til den rette sagsbehandler med det samme og dermed spare en del ressourcer – både ved at færre sager skal gå i tilbageløb, og ved at de erfarne kræfter kan koncentrere sig om avancerede sager.
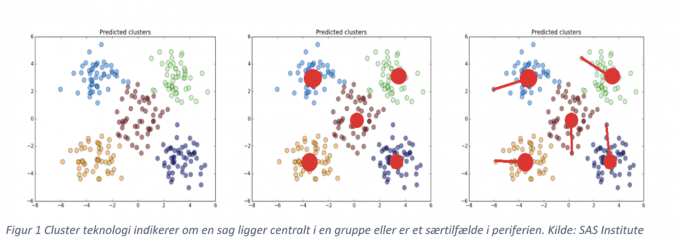
Teknologien, man vil anvende til segmentering af sagerne, er for eksempel cluster- analyse. Ved at gennemgå indholdet af klagesagerne og kortlægge, hvilke sager der ligger tæt på hinanden rent fagligt, kan man gruppere sagerne efter behovet for faglighed (markeret ved forskellige farver i første billede). Nogle klagesager vil være centralt placeret i et givet fagområde – de sager vil have mange fællestræk med de øvrige sager i deres område og dermed udgøre en ”normal” klagesag for sagsbehandleren (markeret med røde pletter i andet billede).
Hvis der er sager, der ligger i en gruppering, men placerer sig langt fra centrum, vil det være sager, der har utraditionelle træk for kategorien af sager, og de vil derfor typisk kræve en erfaren sagsbehandler. Derfor kan de sager lige så godt overgå til den rette sagsbehandler med det samme, frem for først at blive behandlet hos en mindre erfaren sagsbehandler.
Når en tekstanalytisk motor går i gang med at finde relaterede sager, foretager den også nogle fravalg. Den beslutter, hvilke elementer i klagesagen der er relevante at fremhæve som karakteristiske, og så matcher den sagen op mod sager med samme karakteristika.
Det dataetiske problem i relation til fravalget består i risikoen for forkerte afgørelser. Den machine learning-baserede model kan dog også ses som et væsentligt bidrag til at skabe gennemskuelighed i forhold til sagens udfald og dens konsekvenser for den berørte borger.
Til forudsigeligheden knytter sig selvfølgelig også en udnyttelsesproblematik. Hvis en rådgiver – f.eks. en bistandsadvokat – kan få indblik i, hvad der karakteriserer de sager, hvor afgørelsen falder ud til klagerens side, vil det være muligt for nogle rådgivere at give ganske præcis rådgivning om den sproglige udarbejdelse af en klage, der sikrer, at klagen bliver tolket på en bestemt måde af den kunstige intelligens.
Prædiktive modeller
Prædiktive modeller kan bruges til at prioritere imellem sagerne og anvendes parallelt med segmentering. Baseret på tidligere afgørelser kan man identificere de variable, der har med den enkelte sag at gøre, og på den måde ’forudsige’, hvilke sager der har mange træk til fælles med de sager, der ender med påbud eller afslag.
Sådanne prædiktive modeller baserer sig på algoritmer og kategoriseres som selvlærende modeller eller ”supervised” modeller. Efterhånden som sagsbehandlingen automatiseres, stiger antallet af sager med afgørelser, og modellerne bliver derfor bedre til at identificere sager, der potentielt ender med påbud eller afslag.
Til disse modeller er der knyttet dataetiske problemstillinger, fordi de scorer eller profilerer personer og indhold i sagerne. Da profilering og prædiktion kan have store konsekvenser for de involverede parter, er det en dataetisk fordring, at de anvendte algoritmer er ”explainable”.
Man kan anvende forskellige algoritmer til at drive de prædiktive og selvlærende modeller. Nogle af dem giver detaljeret information om, hvilke variable der bidrager med hvilke vægte i scoringsmodellen, mens andre ikke er selvforklarende. Hvis man vælger at gøre brug af en algoritme, der ikke i sig selv forklarer, hvilke variable der vægter noget i scoringsmodellen, kan man anvende såkaldt xAI – explainable AI.
xAI giver input til, hvilke egenskaber i modellerne der bidrager til at forklare modellens resultater. Det er en forholdsvis ny disciplin og indeholder en del potentiale i forhold til at give indsigt i modellernes funktionsmåder – både hvad angår korrelationen og kausaliteten mellem input og de resultater, der kommer ud af modellerne.
Fra et dataetisk synspunkt udgør xAI et væsentligt element i at sikre ligeværdighed og undgå bias eller fordomme om personer og deres baggrund eller kontekst. Analyser af de anvendte variable og vægtningen kan f.eks. integreres i udviklingsfasen, i regelmæssige tests og kan også underkastes revision.
Dette synspunkt er anden del af en tredelt føljeton. DataTech bragte det første synspunkt i serien den 12. november , mens sidste del publiceres den 26. november.

Birgitte Kofod Olsen
Tlf: (+45) 25260903
E-mail: bko@carve.dk
LinkedIn

Mads Krogh Munch Nielsen
Tlf: (+45) 20542422
E-mail: mkn@carve.dk
LinkedIn
Birgitte Kofod Olsen
Birgitte Kofod Olsen er cand.jur. og ph.d. i persondatabeskyttelse og biometri. Hun er partner i Carve Consulting, hvor hun rådgiver danske virksomheder, myndigheder og organisationer om implementering af EU’s persondataforordning (GDPR) og integrering af dataetiske principper i IT og AI-udviklings-processer. Birgitte er forfatter til flere publikationer om persondatabeskyttelse og dataetik, senest Håndbog i dataansvarlighed (Djøf november 2019) og medstifter af tænkehandletanken DataEthics.
Mads Krogh Munch Nielsen
Mads Krogh Munch Nielsen er cand.polit. og partner i Carve Consulting. Han hjælper danske og internationale organisationer med avancerede analytiske løsninger, der arbejder med Compliance, Fraud og Anti Money Laundering. Mads anvender Machine Learning, AI og algoritmiske modeller til Automatiseret beslutningsstøtte, strategi, optimering, og transformation af organisationer og forretninger i såvel den offentlige sektor som med private virksomheder.