
Publiceret på https://pro.ing.dk/4205
Dette synspunkt er det første af en tredelt føljeton, hvor de dataetiske udfordringer ved automatiseret beslutningsstøtte til sagsbehandling vendes. I denne første del er fokus på blandt andet sentimentanalyse.
Vi har i Danmark en tradition for, at beslutninger skal tages af rigtige levende sagsbehandlere, og der er kun blevet flere beslutninger at tage – samtidig med at beslutningerne er blevet mere komplekse – i takt med at flere og flere informationer løber til igennem nyoprettede digitaliseringsspor.
Sagsbehandlerne er lige nu i farezonen for at blive de store tabere i informationskapløbet. Det vælter ind med data i alle mulige afskygninger, og det meste har relevans for sagsforløbene. Men informationen skal processeres, og i udgangspunktet er det kun den manuelle ressource – sagsbehandleren – der kan løfte den opgave.
Potentialerne ved automatiseret beslutningsstøtte – og faldgruberne
Hvis noget skal ændres i den sammenhæng, må det komme fra teknologier, der kan gøre beslutningsprocessen enten hurtigere eller mere kvalificeret – i bedste fald begge dele.
Automatiseret beslutningsstøtte, dvs. anvendelsen af avanceret analyse og selvlærende algoritmer, er en åbenlys vej at overveje. Men i hvilket omfang kan vi hjælpe myndighederne med at effektivisere og sagsbehandlerne med at fjerne kompleksitet uden at kompromittere sagligheden i beslutningsarbejdet? Og hvilke dataetiske konsekvenser er der knyttet til brugen af teknologierne?
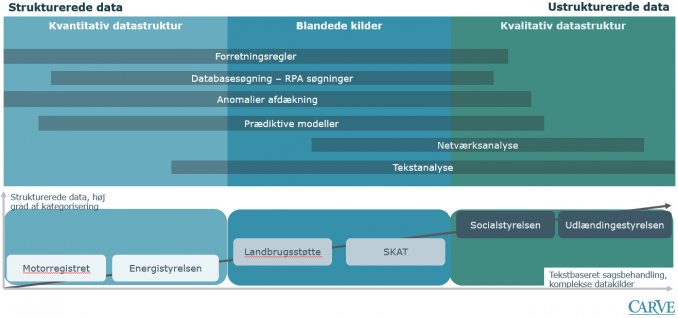
I besvarelsen af disse spørgsmål er det først og fremmest værd at forholde sig til, hvilke teknologier vi bringer i anvendelse, når vi taler om beslutningsstøtte. I sagens natur må vi også forholde os til, hvilken del af den offentlige sektor, vi har i fokus.
Vi kan for eksempel ikke tage én styrelse og lade den repræsentere alle andre styrelser. Hver styrelse er per definition ansvarlig for et unikt område, og derfor vil der næsten altid være nuanceforskelle på, hvilke teknologiske landvindinger der vil kunne skabe værdi.
Anvendelsen af avanceret analyse
Det er ikke alle forvaltningsopgaver og tilsyn, der er baseret på ustruktureret tekst. Men det er tilfældet mange forskellige steder som eksempelvis i sundhedsvæsenets patientjournaler, i kommunernes socialkontorer, hvor nomadefamilier opbygger tommetykke sagsmapper skrevet af deres tidligere socialrådgivere, og i Udlændingestyrelsen, hvor den enkelte asylsag behandles individuelt og i sagsmapper.
I sådanne sager er det en kæmpe landvinding at opbygge en selvlærende tekstanalysemodel til at gennemlæse alle de skriftlige dokumenter, der findes i hver sag, finde lignende sager med tilhørende afgørelser og oversætte eventuelle udenlandske dokumenter til dansk – for så at afslutte med at formulere et beslutningsreferat med de væsentligste elementer, modellen har fundet i sagen.
Sentimentanalyser reducerer sagsbehandlingstiden
I de myndigheder og forvaltningsenheder, hvor sagsbehandlingen evolverer omkring tekstbaserede journaler, går en meget stor del af sagsbehandlingstiden med, at sagsbehandleren sætter sig ind i sagsforløbet og noterer sig de afgørende elementer. Det tager en vis tid at læse flere hundrede siders sagsforløb – og det koster en god del fokus at fastholde helhedsbilledet af forløbet.
Et fokus, som kun de færreste sagsbehandlere får mulighed for at bevare i en travl hverdag, der ofte bliver afbrudt af hastesager eller forløb, der kræver ekspertise til en given beslutning, før den kan ekspederes videre.
Ved brug af sentimentanalyser kan tidsforbruget i sagsbehandlingen minimeres væsentligt, fordi analyseprogrammet er udviklet, så det forstår sætningerne i journalen. Det kan således give støtte til at identificere de væsentlige informationer i sagen og fremfinde tidligere, relevante sager og på den måde medvirke til hurtig afgørelse af den aktuelle sag.
Et dataetisk problem i anvendelsen af sentimentanalyse opstår, hvis man bruger en generel sprogvektor i en forvaltningsenhed med et selvstændigt fagsprog. De såkaldte sprogvektorer bruges til at definere relationer i sproget – for eksempel hvilke termer der anvendes om specifikke situationer.
Hvis man anvender en sprogvektor, der er trænet på et irrelevant materiale i forhold til et specifikt forvaltningsområde, vil sagen blive analyseret forkert. Et eksempel er, at man i forbindelse med en klagesag om arbejdstilsyn i en kemikalievirksomhed vil finde en overrepræsentation af ord, der relaterer sig til dårligt arbejdsmiljø – ganske enkelt fordi branchens sprog er relateret til kemikalier
Et andet eksempel er tildeling af en høj score til en konkret person i forhold til optagelse på overvågningsliste alene på grund af personens bopæl. Hvis bopælen i de underliggende dokumenter er knyttet til termen ghettoplan, er der risiko for, at den prædiktive model fører til diskrimination.
Det kræver transparens i de anvendte analytiske teknologier og en systematisk og regelmæssig tilpasning og auditering af følsomheden i modellerne at undgå, at de fører til forkerte afgørelser eller til anden form for utilsigtet bias som eksempelvis diskrimination.
Content Categorisation til visitering af sager
Det er ofte en tidsrøver at få placeret sager i de rette hænder. En sag, der ankommer i indbakken hos eksempelvis en styrelse, kan have elementer, der placerer den hos en given sagsbehandler, men ved nærmere gennemlæsning viser det sig, at den hører til hos en anden med en særlig faglig profil.
Det giver det paradoks, at styrelsens mest omnipotente medarbejdere går hen og bliver flaskehals for de mindre erfarne, mere specialiserede sagsbehandlere, der lettere indgår i en ‘masseproduktion’ af sager med enslydende karakter.
I sådanne situationer kan den avancerede analyseform Content Categorisation med fordel anvendes.
Analyseprogrammet forstår nemlig de emner, der er til stede i sagen, og kan relatere dem til andre lignende sager. Det vil derfor kunne automatisere visiteringen af sagerne til rette sagsbehandler.
Effekten af sådan en løsning vil være meget værdifuld. Allerede nu har Skatteankestyrelsen implementeret RPA-robotter, der indhenter oplysninger til sagsbehandlingen fra Skat, Google Maps mv. Det gør robotterne på minutter, hvor sagsbehandlerne tidligere brugte timer.
Dataetisk risikovurdering
Både sentimentanalyser og Content Categorisation er eksempler på avancerede teknologier, der umiddelbart skaber stor værdi, men også medfører nye risici for de involverede borgere.
Implementeringen af dem bør derfor medtænke en dataetisk risikovurdering, hvor konsekvenserne for borgeren kortlægges i forhold til deres kontrol med egne data og forståelse for, hvad der lægges vægt på i sagsafgørelsen, og hvorfor sagen evt. afgøres til ulempe for dem.
Dette synspunkt er en del af en tredelt føljeton. DataTech bringer det næste synspunkt i serien den 19. november, mens sidste del publiceres den 26 november.

Birgitte Kofod Olsen
Tlf: (+45) 25260903
E-mail: bko@carve.dk
LinkedIn

Mads Krogh Munch Nielsen
Tlf: (+45) 20542422
E-mail: mkn@carve.dk
LinkedIn
Birgitte Kofod Olsen
Birgitte Kofod Olsen er cand.jur. og ph.d. i persondatabeskyttelse og biometri. Hun er partner i Carve Consulting, hvor hun rådgiver danske virksomheder, myndigheder og organisationer om implementering af EU’s persondataforordning (GDPR) og integrering af dataetiske principper i IT og AI-udviklings-processer. Birgitte er forfatter til flere publikationer om persondatabeskyttelse og dataetik, senest Håndbog i dataansvarlighed (Djøf november 2019) og medstifter af tænkehandletanken DataEthics.
Mads Krogh Munch Nielsen
Mads Krogh Munch Nielsen er cand.polit. og partner i Carve Consulting. Han hjælper danske og internationale organisationer med avancerede analytiske løsninger, der arbejder med Compliance, Fraud og Anti Money Laundering. Mads anvender Machine Learning, AI og algoritmiske modeller til Automatiseret beslutningsstøtte, strategi, optimering, og transformation af organisationer og forretninger i såvel den offentlige sektor som med private virksomheder.